
Cambridge, MA, May 2020 |
I am a research scientist at NVIDIA Research, where I lead training of intelligent and efficient foundation models. I earned my Ph.D. in Computer Science from Harvard University in 2023, where I was advised by H.T. Kung and honored as a recipient of the Harvard James Mills Peirce Fellowship. I also gained valuable research experience at univerisities like Nanyang Technological University, UC San Diego and companies like Meta/Facebook, Tencent.
Email: xind [at] nvidia.com, xindong [at] alumni.harvard.edu |
News
- Jun 2025 » We released Nemotron-Reasoning-1.5B (Top10 trend), trained using "Prolonged RL," where we, for the first time, scaled up RL steps (+2k) and problems (+130k). It is the best 1.5B model with accuracy on par with DeepSeek-R1-Distill-Qwen-7B.
- Apr 2025 » We released CLIMB, a robust LLM pre- and post-training dataset building method. We have now completed the puzzle of data preparation, model architecture, training recipes, and alignment to achieve state-of-the-art SLM.
- Jan 2025 » Gave a talk at Scale ML + MLSys @ MIT on our Hymba work.
- Nov 2024 » We released the first hybrid-head model, Hymba-1.5B (accepted by ICLR 2025 as spotlight), which outperforms LLaMA 3.2-3B, despite being trained on 7× fewer tokens and achieving 12× cache reduction.
- Oct 2022 » Our Additive Power-of-Two Quantization (ICLR'20) is now supported by offical PyTorch APIs.
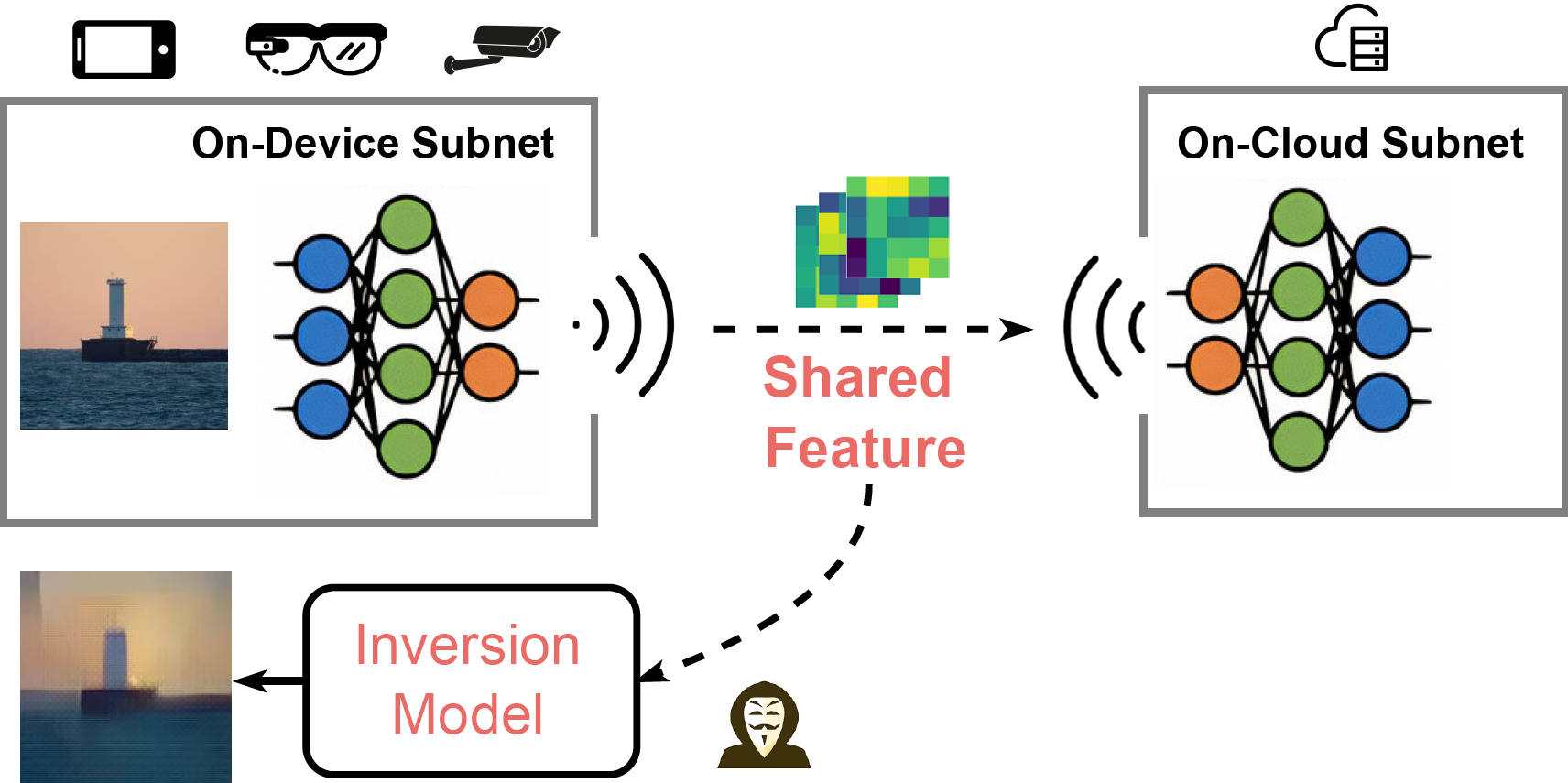
- Oct 2022 » Our Direct Model Inversion is accepted by BMVC 2022 and featured by MIT Technology Review, SingularityHub.
Experiences

NVIDIA

Sony

Meta Reality Lab
NVIDIA
Tencent America
Projects
Social Media Highlights

Hymba: A Hybrid-head Architecture for Small Language Models
International Conference on Learning Representations (ICLR 2025 Spotlight)
- Hymba-1.5-1.5B (release soon) achieves better performance than LLaMA 3.2-3B and Qwen-2.5-1.5B with 10x less kv cache memory usage.
- Falcon-H1 (up to 34B) from UAE adopted a similar parallel architecture as Hymba with impressive performance.



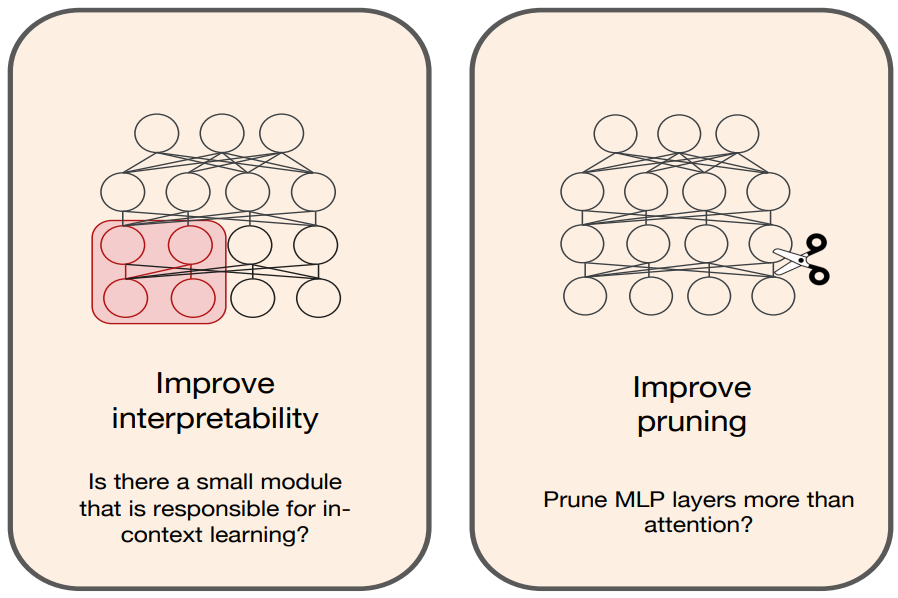
Unraveling the Mechanics of Learning-Based Demonstration Selection for In-Context Learning
Annual Meeting of the Association for Computational Linguistics (ACL 2025 Oral)



A Deeper Look at Depth Pruning of LLMs
ICML 2024 Workshop on Theoretical Foundations of Foundation Models (ICML Workshop 2024)



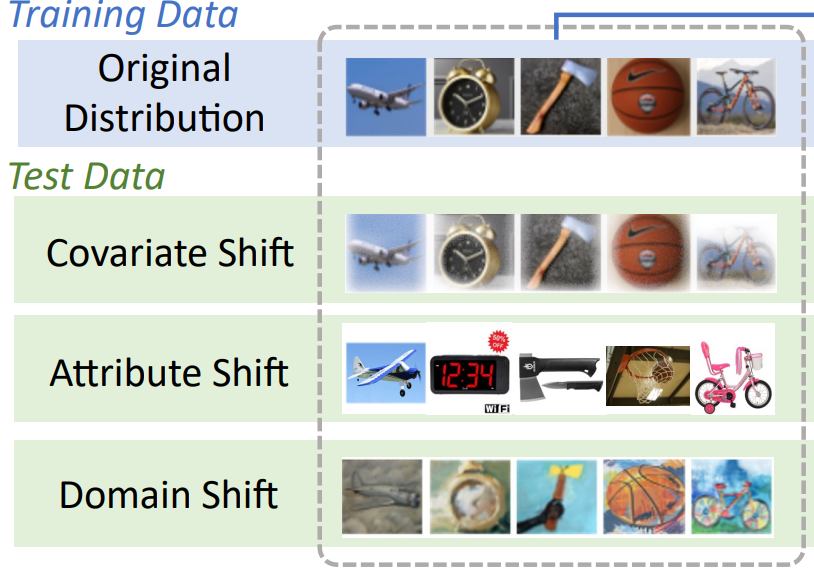
Is Heterogeneity Notorious? Taming Heterogeneity to Handle Test-Time Shift in Federated Learning
Conference on Neural Information Processing Systems (NeurIPS 2023)
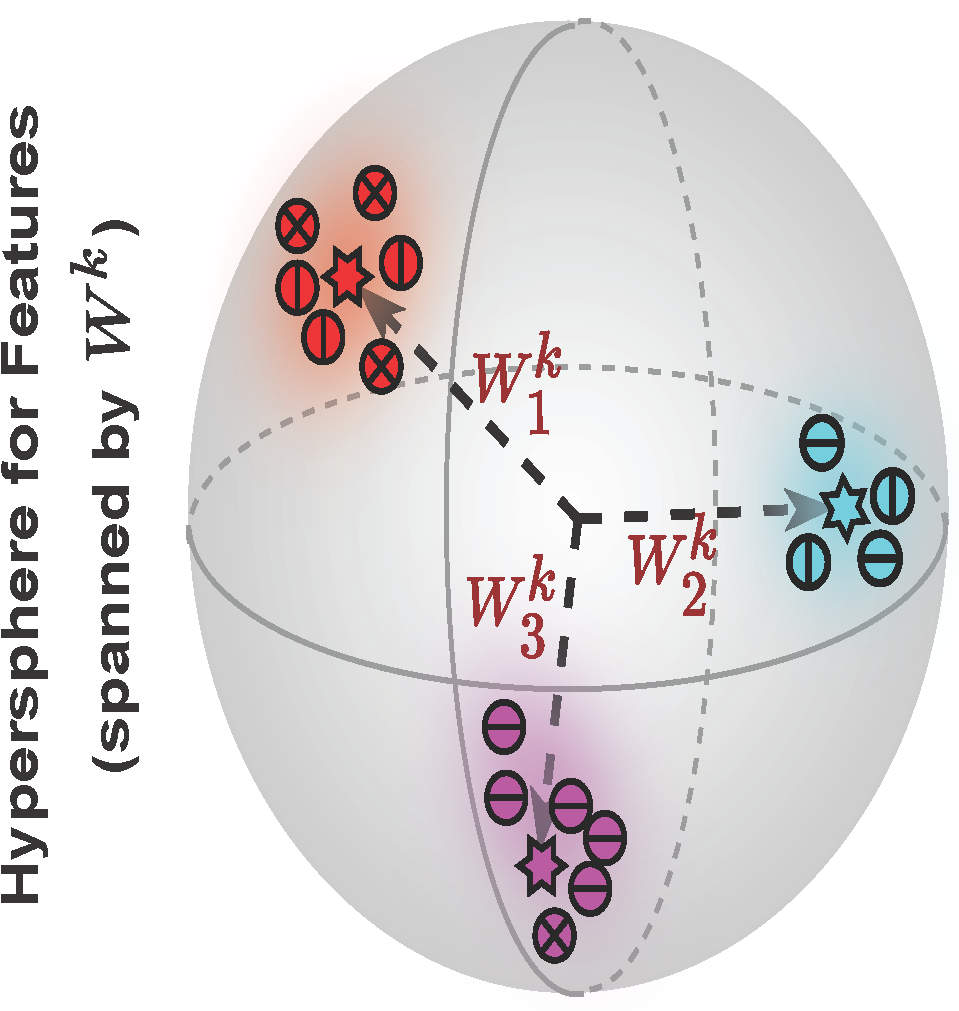
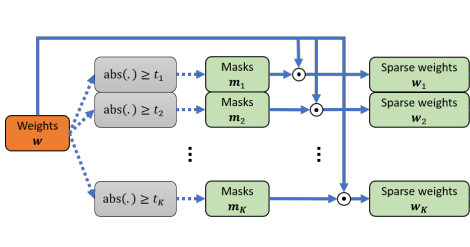
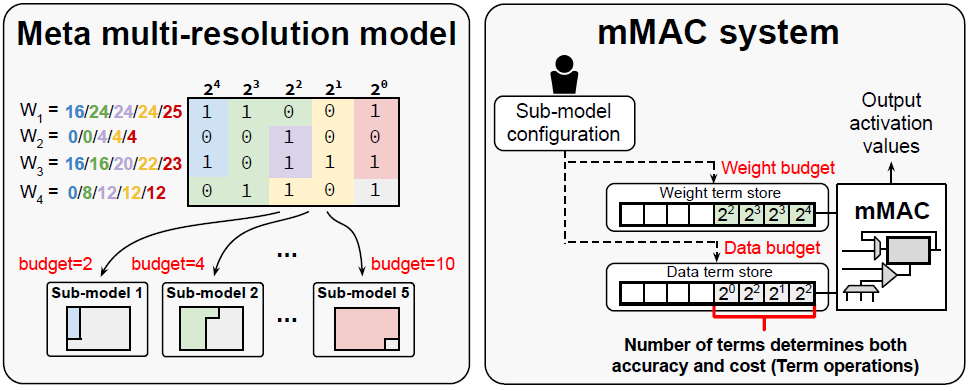
Training for Multi-resolution Inference Using Reusable Quantization Terms
The 26th ACM International Conference on Architectural
Support for Programming Languages and Operating Systems (ASPLOS 2021)
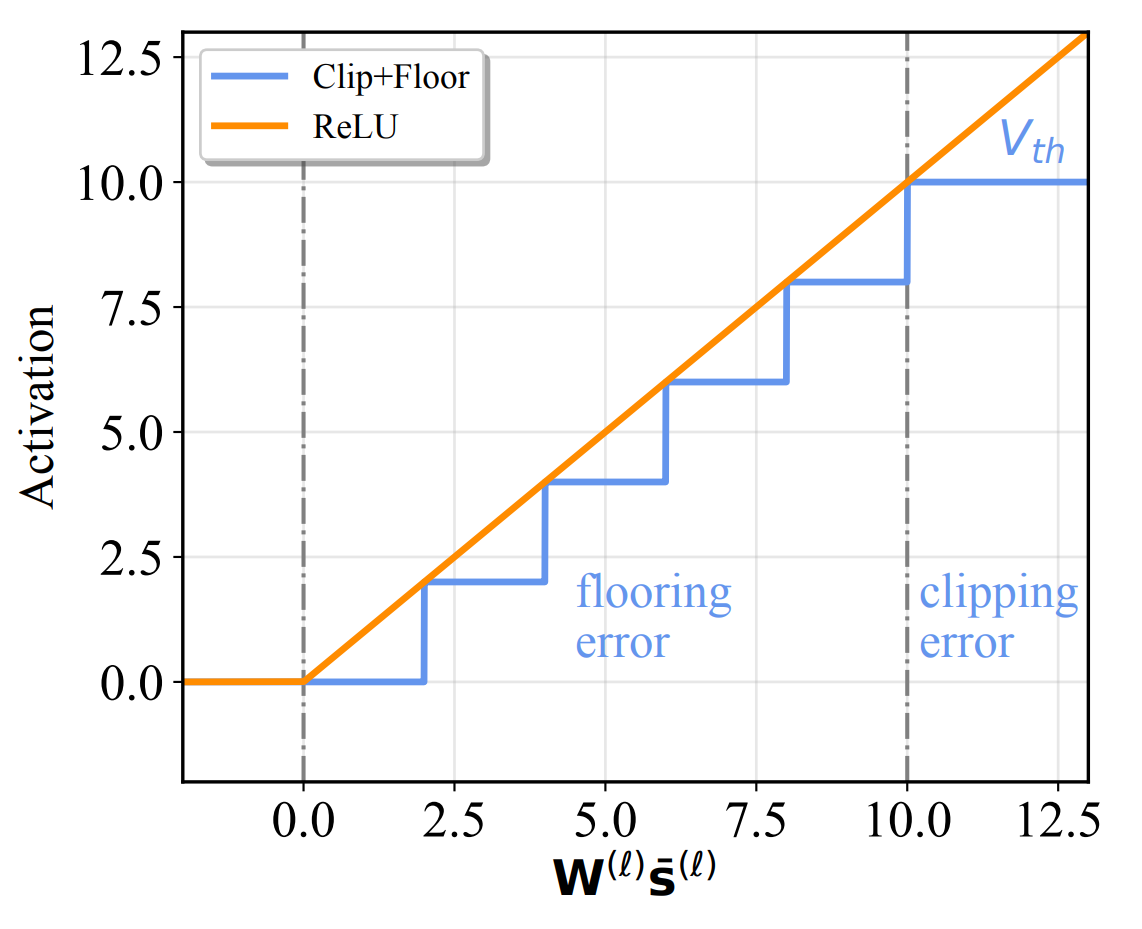

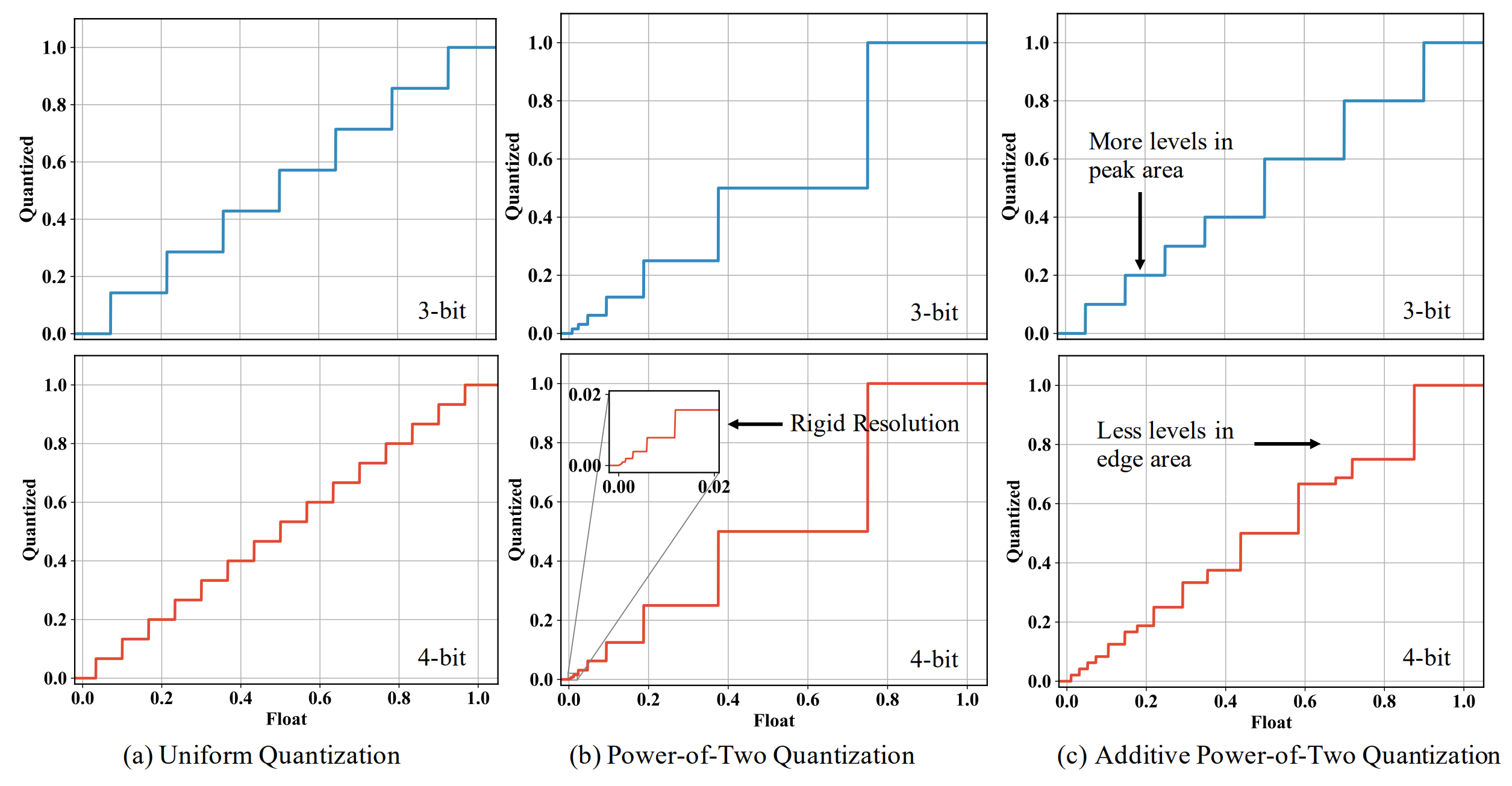
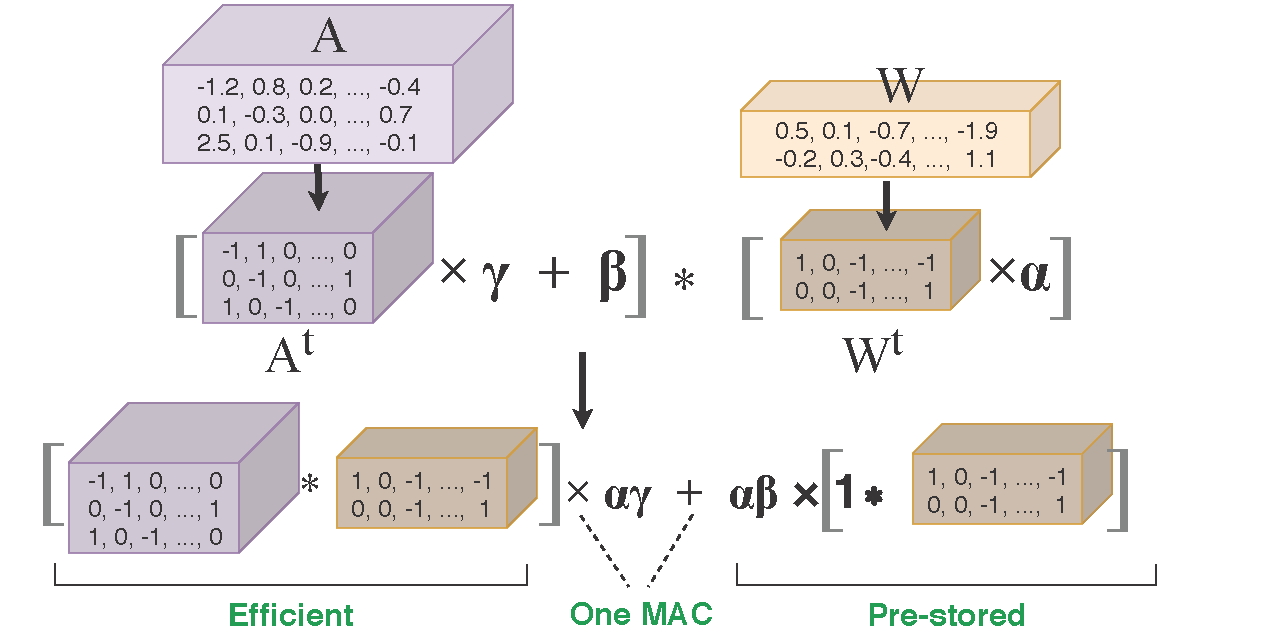
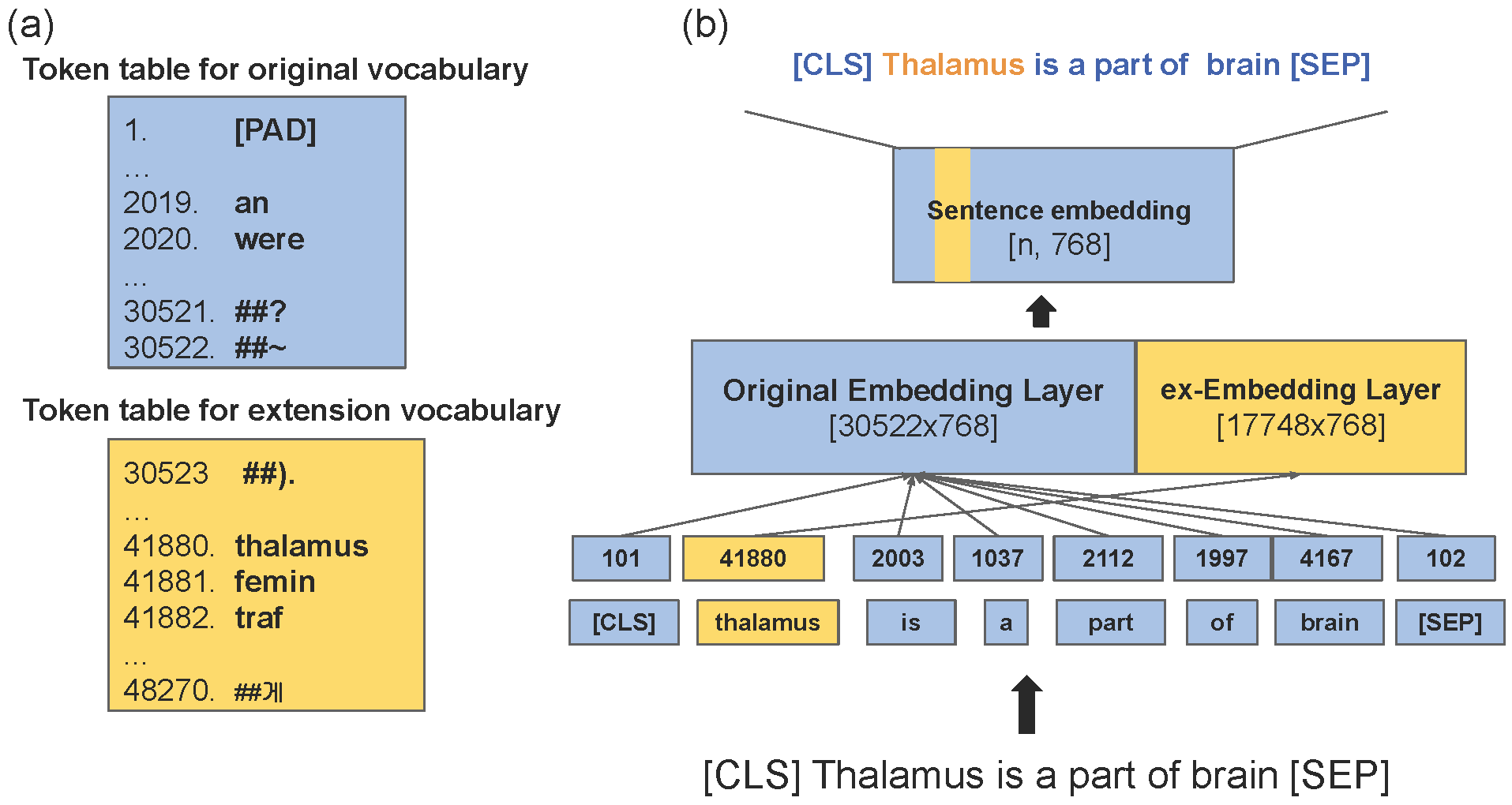
exBERT: Extending Pre-trained Models with Domain-specific Vocabulary Under Constrained Training Resources
The 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP 2020)
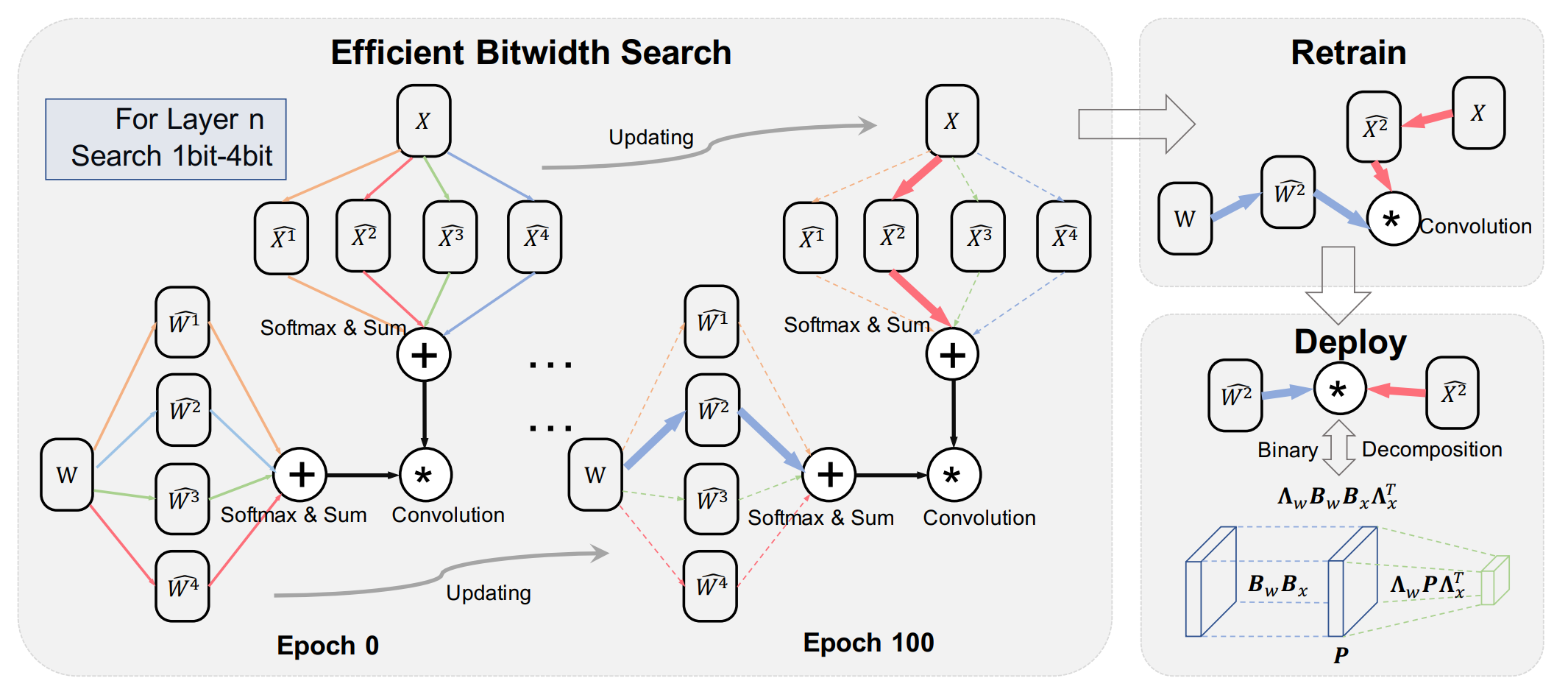
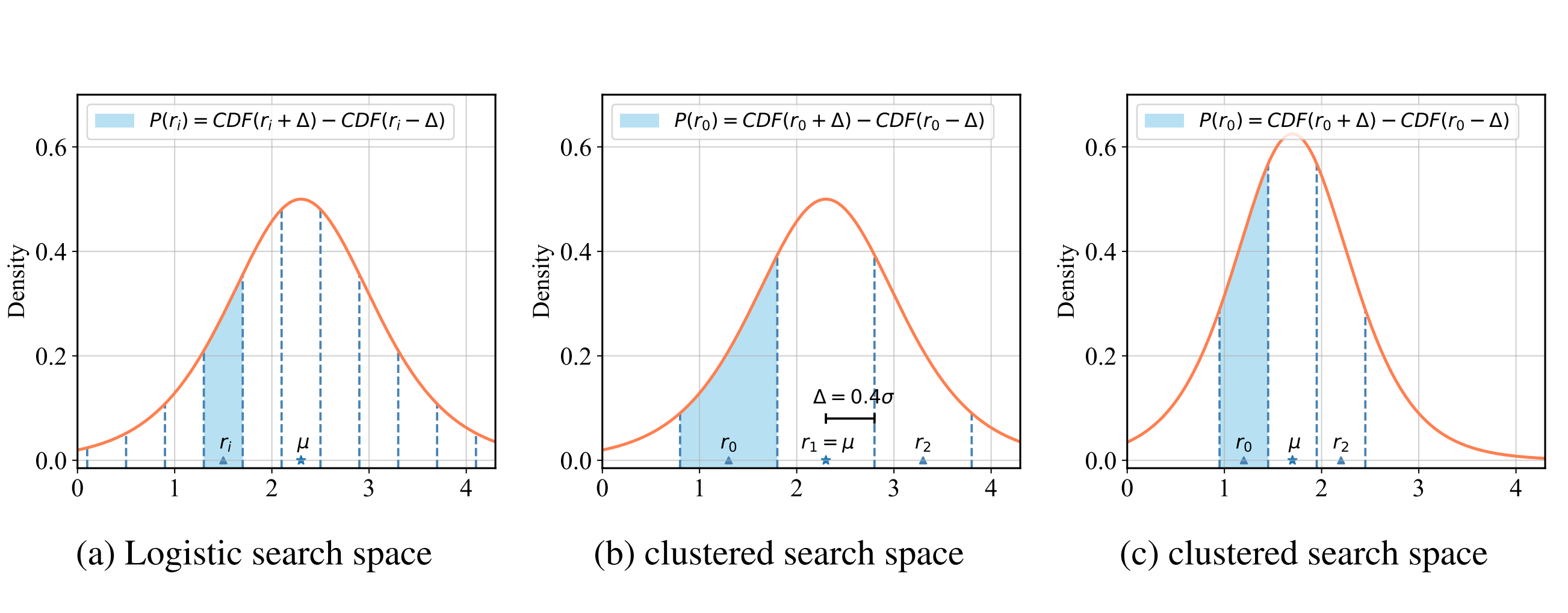
Differentiable Dimension Search for Binary Neural Networks
1st Workshop on Neural Architecture Search at ICLR 2020 (ICLR 2020 Workshops))
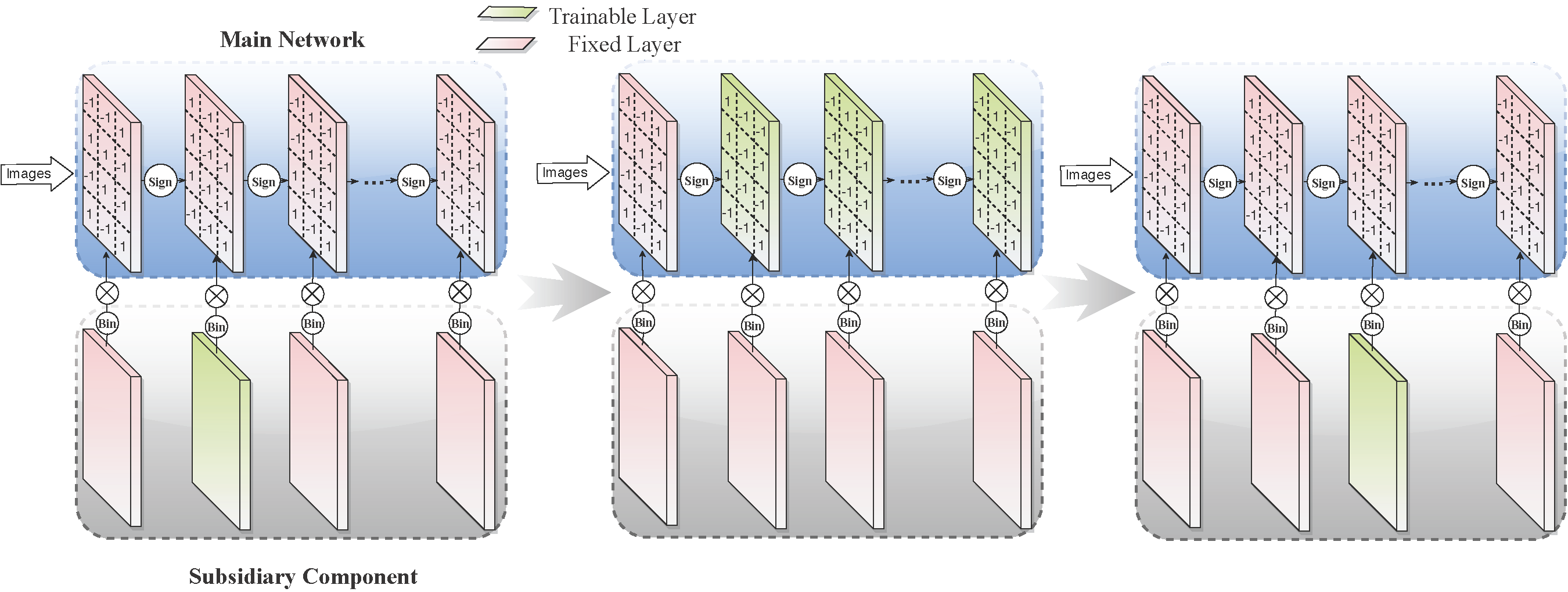
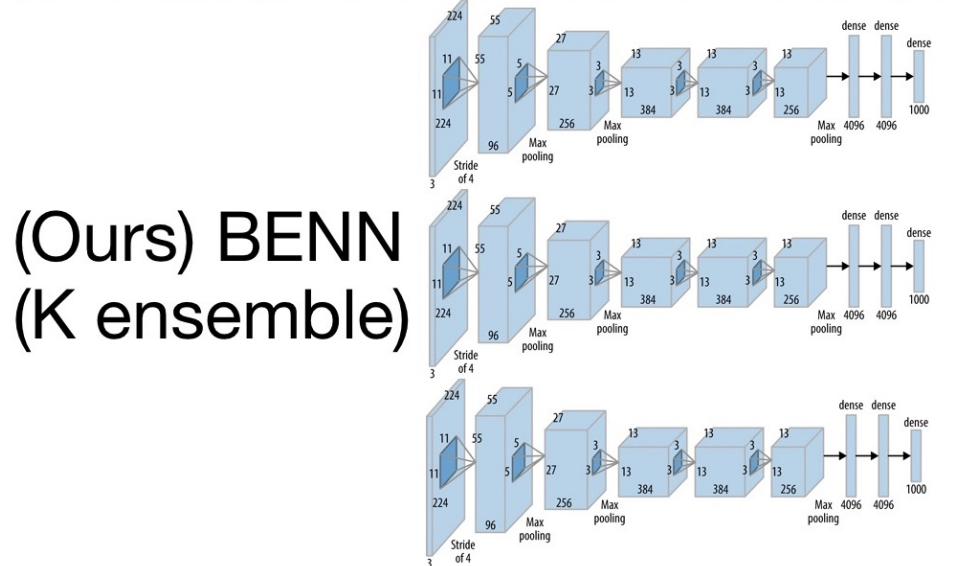
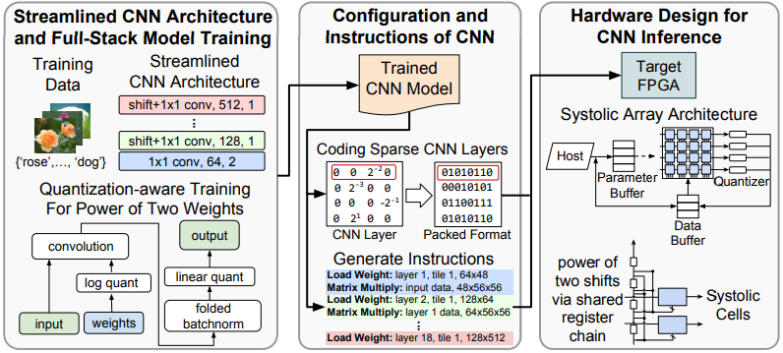
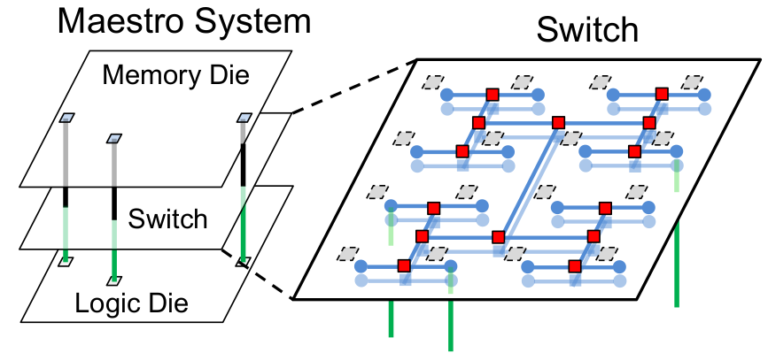
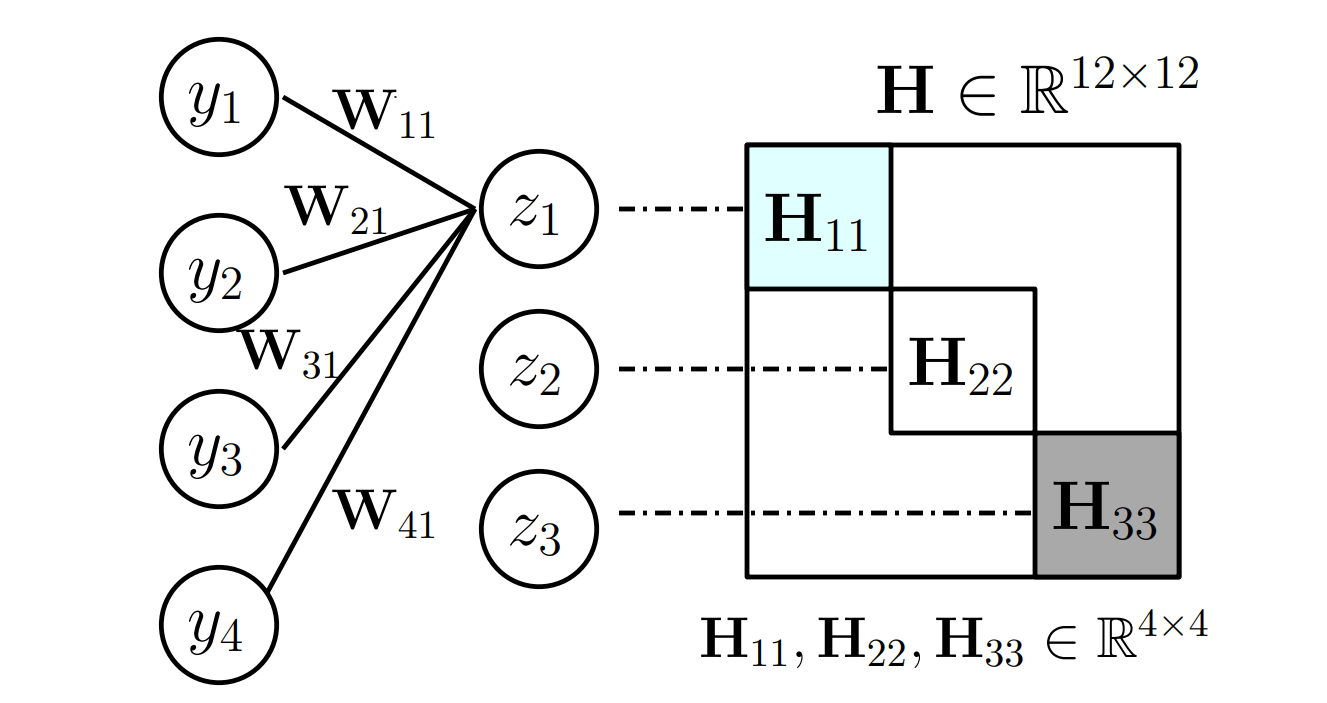
Learning to Prune Deep Neural Networks via Layer-wise Optimal Brain Surgeon
Thirty-first Conference on Neural Information Processing Systems (NeurIPS 2017)
Academic Services
- Reviewer/Area Chair for ICML, NeurIPS, AAAI, IJCAI, CVPR, ICCV, ECCV, EMNLP, ACL
- Co-organizer of the 1st international workshop on The Practical Deep Learning in the Wild (PracticalDL-22) at AAAI 2022
- Teaching Fellow of Harvard CS242 Compute at Scale